One of the simplest probability distributions to begin with is the discrete Bernoulli distribution, named after Jacob Bernoulli (1655-1705). It can be thought of as a coin toss where the coin either comes up heads (with value 1) or tails (with a value of 0). Other distributions like the binomial can be built up as multiple Bernoulli trials (or the multinomial distribution which is built from a binomial with more than two outcomes).
So, if 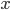 is the outcome of a coin toss (a Bernoulli trial) and "heads" gives a value of
is the outcome of a coin toss (a Bernoulli trial) and "heads" gives a value of  , we can say the probability of
, we can say the probability of  is
is 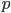 ;
;
 .
.
All of the outcomes must sum to one (100%) so the probability of tails,  , is the probability the outcome is not heads:
, is the probability the outcome is not heads:
 .
.
For a fair coin 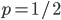 . However, this formulation is general so we could have a trick coin with
. However, this formulation is general so we could have a trick coin with  , for example.
, for example.
So what is the expected value of a Bernoulli trial (a coin toss)? This is pretty intuitive but it doesn't hurt to write it out in systematic "bookkeeping" fashion. If we flipped the same coin many times and kept track of the outcomes, fraction of the time . The rest of the time, 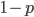 , the outcome is . So amount of time we have a value of and is the amount of the time . Weighting these outcomes by the frequency we expect to see them gives us an average result of:
, the outcome is . So amount of time we have a value of and is the amount of the time . Weighting these outcomes by the frequency we expect to see them gives us an average result of:

The zero cancels out 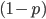 so we are left with:
so we are left with:
 .
.
So, if we have a fair coin with we expect and average outcome of value  . This seems to make sense.
. This seems to make sense.
The average ( ) is another way of saying the expected value of a trial or the "expectation."
) is another way of saying the expected value of a trial or the "expectation."
 .
.
Now for the variance, or degree of spread around the average. Variance is often symbolized by a lower case sigma-squared,  . The standard deviation,
. The standard deviation,  , is the square root of the variance.
, is the square root of the variance.
Variance is calculated as the average squared difference of individual outcomes,  , from the mean.
, from the mean.

We already know from the mean derivation above that  . So we can substitute this in:
. So we can substitute this in:

We also know that  amount of the time
amount of the time  , which gives us one side of the two mutually exclusive (add the probabilities) outcomes:
, which gives us one side of the two mutually exclusive (add the probabilities) outcomes:
 ...
...
Also,  amount of the time
amount of the time  so the full equation becomes:
so the full equation becomes:

Multiplying this out and simplifying gives:






Like heterozygosity in Hardy-Weinberg genotype frequencies, the variance is at its greatest values at intermediate frequencies near and declines to zero at 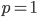 and
and 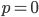 .
.
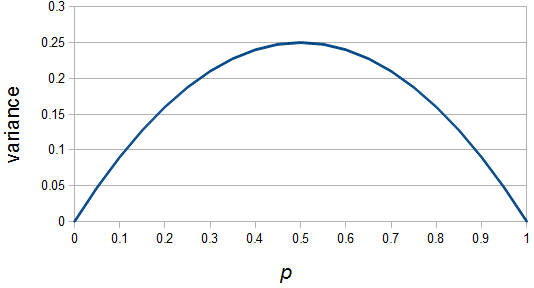
If is indeed zero or one than the outcome is always identical to the mean and therefore variance is zero--there is no deviation in individual outcomes from the average. On the other hand if 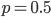 every outcome will be a value with a distance of 0.5 from the mean (either
every outcome will be a value with a distance of 0.5 from the mean (either  or
or  with
with  ) and this distance squared is 1/4,
) and this distance squared is 1/4,  .
.